


Table of contents
- What is a graph database?
- How does a graph database work?
- Types of graph databases
- The graph data model vs the relational data model
- Key differences between graph databases and relational databases
- Advantages of graph database over relational databases
- When should you use the graph database?
- Conclusion
- FAQ Section
- You May Also Like:
- How NebulaGraph Works
The place of data in driving business growth is evident in the way that many organizations are aggressively collecting and utilizing data. As data becomes more accessible and easier to analyze, it is playing an increasingly important role in helping organizations to identify trends, understand customer behavior, optimize products and maximize profits. In many ways, data has become the "new oil" - a valuable commodity that can be used to drive growth and competitive advantage. Prudent data organization, manipulation and management are at the heart of commoditizing this new oil. It would not have been possible to realize the kind of ground-breaking data-driven applications we are witnessing today without database tools. From social networking sites to recommendation engines across e-Commerce marketplaces, it’s all about creating value out of data and databases are central here. In fact, the database management systems global market is expected to grow at a CAGR of 12.2 percent and reach 142.7 trillion US dollars by 2027.
Depending on what you want to achieve with your data, you might often end up at a crossroad where you’ll have to choose between databases. Graph database vs. relational database is one such crossroad that many may be struggling with. Let’s distinguish these two and help you choose the right one.
What is a graph database?
A graph database is a NoSQL database where data is stored as a network graph. A typical graph database contains edges, nodes, and properties that present and store data. Relationships are first-class citizens in a graph database and are identified with unique keys. By making relationships first-class citizens, graph databases can more efficiently store, retrieve, and traverse data. Graph databases excel at handling data with complex relationships and are therefore useful for applications such as social networking, recommendation engines, and fraud detection among many more.
An open source graph database is always the best place to start as they come with a supportive community that ultimately creates the perfect ecosystem.
How does a graph database work?
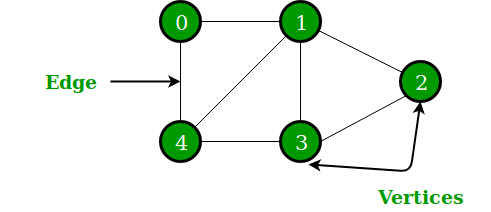
Graph databases work by using two essential elements: nodes and edges. The nodes in a graph represent entities, and the edges represent relationships between those entities. This allows for more flexible and efficient querying. For example, in a social network, each user would be represented by a node, and the edges would represent the relationships between users. A graph database could then easily answer questions such as "Who are the friends of my friends?" or "What path connects me to another user?"
They perform traversal queries and apply algorithms to determine patterns, influencers, paths, points of failure, and communities. Understanding these aspects allows users to effectively analyze massive amounts of data.
Types of graph databases
Graph databases can be categorized into two main groups based on data model and storage.
Data model-based graph databases
There are three major types under this category namely the property paragraph, RDF graphs, and hypergraph
1. Property graph
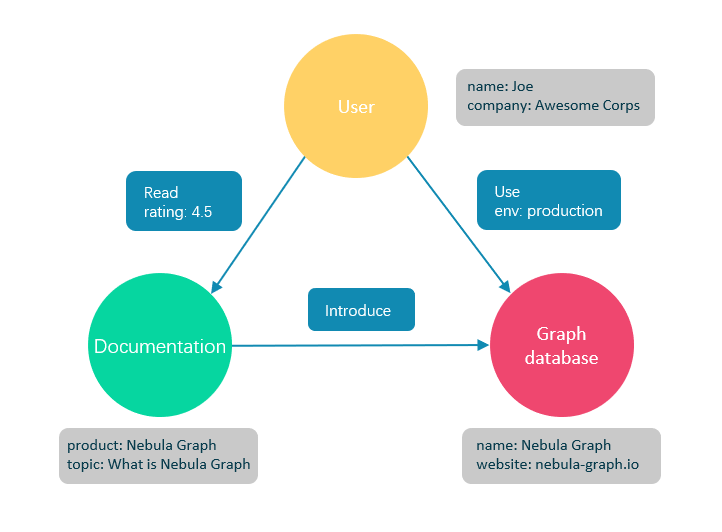
Property graphs organize data in relationships, nodes, and properties and store the data on relationships or nodes.
Nodes are entities and can hold multiple attributes called properties. You can tag nodes with labels that represent their roles in a domain. In addition, labels can attach metadata, like constraint or index information, to specific nodes.
Relationships provide relevant connections between different nodes. The relationship is directed, named, and has a start and end node. Furthermore, relationships have quantitative properties like distances, costs, ratings, weights, strengths, and time intervals. Relationships are efficiently stored, and thus nodes can share relationships without compromising performance. The navigation of relationships can be done in either direction, despite the fact that they are stored in one direction.
2. Hypergraph
Hypergraphs are data models that allow relationships to connect to multiple nodes by allowing several nodes at either end. This will enable users to analyze and store data with numerous many-to-many relationships. The relationships in a hypergraph are referred to as hyperedges.
In contrast to property graphs, hypergraphs have multidimensional edges, making them more generalized. However, the two are isomorphic, meaning you can present a hypergraph as a property graph, but you can’t do the opposite.
3. Resource description framework (RDF)
An RDF, or triple store, stores data in a three-part format of subject-data-object data structure. A separate node is used to present any additional information. RDF graph models are made of Arcs and Nodes, and the graph notation is presented by two nodes, one for the subject and another for the object, and an arc presents the predicate.
Triple stores are categorized as data model-graph databases because they process logically linked data. However, their storage engines are not optimized for property graphs, nor do they support index-free adjacency; thus, they aren’t native graph databases.
RDFs can scale horizontally but can’t rapidly transverse relationships because they store triples as individual elements. They must create connections from independent facts and add latency to perform graph queries. Triple stores are mostly applied in offline analytics because of their shortcomings in latency and scale.
Storage-based graph databases
This category contains three major types as well, namely the native storage graph, relational storage, and key-value store graphs:
1. Native graph storage
Native graph storage uses edge and vertex units to store and manage graph databases. It is best suited for multiple-hop or deep-link graph analytics. Native graph storage is designed to maximize traversal speed in arbitrary graph algorithms.
2. Relational storage
This graph database stores the edge and vertex table using a relational model. During runtime, relational “JOIN” concatenates (links) the two tables. The relational model represents data in tables using an intuitive and easy-to-understand way. Each row is a record with a key, which is the unique ID. Each column holds an attribute of the data, and each record has the attribute’s value. This makes it easy to identify the relationships between data points.
3. Key-value store
A key-value store is a non-relational database that uses NoSQL databases to store data. It stores data in key-value pairs where the key is the unique identifier. The keys and values range from complex compound objects to simple objects. Perhaps the best benefit of a key-value graph DB vs relational DB is that the key-value graph is highly partitionable. As a result, it allows horizontal scaling that most database types cannot achieve.


The graph data model vs the relational data model
Though both graph data and relational models focus on data relationships, they don’t do it similarly.
You decide which entities will be nodes and links and which you will discard in a graph data model. This results in a blueprint that you can use to create visualization models for charts.
A relational data model groups database entries by their relationships using a table of values. Each row in a table represents corresponding data values and denotes a real-world relationship. Table and column names help in interpreting the values in each row.
A graph data model stores relationships at an individual record level. On the other hand, a relational data model uses predefined structures called table definitions. However, you can convert a relational database to a graph database.
Key differences between graph databases and relational databases
The fundamental difference between graph databases and relational databases lies in how relationships are handled. In a graph database, relationships are driven by data points. In a relational database, relationships are driven by columns in data tables.
Here are the differences in detail:
Storage format: A graph database stores entities as nodes and relationships as edges. A relational database stores data in tables with rows and columns and uses “JOIN” for fast querying.
Dataset size: Graph databases are quick even for large datasets, while relational databases are slower.
Index: Graph databases typically use index-free adjacency, meaning that every node is connected to every other node in the database, while relational databases use indexed pointers to connect related data.
Transactions: Graph databases typically don't support transactions very well, while relational databases can perfectly support transactions and even accounting.
Processing power: Graph databases require more processing power and storage space.
Advantages of graph database over relational databases
There are reasons you would choose a graph database over a relational database, and this is informed by the advantages. Here are the key advantages of a relational database vs a graph database:
1. Graph databases are better at handling relationships
When it comes to handling relationships, graph databases are king because of the way they're built. They can easily represent complex relationships between data points.
This is a huge advantage when you're trying to model data that's naturally hierarchical, like social networks or business relationships. With a graph database, you can easily create entities and track the relationships between them. This makes finding and understanding data a lot easier, which is essential when you're trying to make quick decisions based on insights from your data.
In a relational database, you have to define the relationships between tables ahead of time. With a graph database, you can define relationships on the fly, which makes it much easier to handle complex data models.
2. Graph databases are more scalable
This means that graph databases can handle large amounts of data without running into issues. And as data volumes continue to grow, this is an increasingly important factor to consider.
You can easily divide the database across multiple servers while keeping intact vital aspects of compliance such as privacy requirements.
3. Graph databases can be more performant
When it comes to graph database vs relational database performance, data is stored in a graph format in graph databases, which makes it easier to navigate and find connections between data points. Second, the way that data is structured in a graph database makes it possible to index data more effectively. This means that queries can be executed more quickly, which leads to better performance and user experience.
You can actually increase the relationships without compromising the performance.
4. Graph databases offer more flexible data modeling
With a graph database, you can model your data however you want, which means you're not limited to the rigid structures of a relational database. By representing data as a series of interconnected nodes, graph databases can more accurately capture the intricate web of relationships.
5. Graph databases are easier to understand
Things are a lot simpler to understand in a graph database. In fact, you can think of a graph database as a collection of nodes and relationships between nodes. And that's it!
There's no need to worry about tables, columns, or foreign keys. Just create your nodes and relationships and you're good to go. This makes data management a breeze and makes it easy for other people to understand what you're trying to do.
6. Graph databases can be more trusting
Graph databases can be more trusting because they are based on a one-table model. In a graph database, the table is called a graph, and it contains all the information about entities and the relationships between them.
This makes it much easier to find information because there is no need to join tables or run complex queries. All you need to do is find the node that you're interested in and look at the relationships associated with it.
7. Graph databases can better handle data consistency
Let's say you're a retailer and you have a customer database. A relational database would be fine for storing information about your customers, but it wouldn't be the best tool for handling customer-product interactions.
Why? Because a relational database is based on a normalized model, which means that data is divided into tables and columns. And this can lead to inconsistencies when you're trying to query data. For example, if you want to get a list of all your customers for a particular product, you might have to query two or three different tables.
A graph database, on the other hand, is based on a non-normalized model, which means that data is stored in one place. This makes it much easier to query data, because everything is in one place.
8. Graph databases can be more extensible
What this simply means is that they can handle more data combinations. For example, let's say you want to track the relationships between people, organizations, and things. A graph database would be perfect for this task, whereas a relational database would quickly become overloaded.
Graph databases are also great for managing data that changes rapidly, such as social media data or sensor data. This is because they can quickly adapt to changes in the data model, without having to perform a full database rebuild.
When should you use the graph database?
Graph databases are well suited for applications that require the storage and retrieval of data that can be represented as a graph, such as social networks, maps, and networks. They are also well suited for applications that require the analysis of data that is connected in complex ways, such as fraud detection and recommendation engines.
For example, in a social network, a user's friends are also friends with each other. A graph database can quickly find all the friends of a user's friends. In contrast, a relational database would need to perform multiple joins to find the same information. By prioritizing relationships, graph databases can provide greater insight into data. In general, any application that would benefit from being able to represent data as a network of interconnected nodes would be a good candidate for a graph database.
Conclusion
Understanding graph database vs relational database is the first step to building effective data models that will provide valuable insights into connected data. It is also important to note that the two are not alternatives, but each serves a different purpose.
The most important point that you’ll always need to bear in mind in graph vs relational databases is that graph databases are better suited for applications that require multiple relationships between data points, while relational databases are better for applications with less complex data structures.
FAQ Section
How does a graph database differ from a relational database?
A graph database uses graph structures for semantic queries with nodes, edges, and properties to represent and store data. A relational database, on the other hand, uses tables and relations between them to store data. Graph databases are used to query complex relationships, whereas relational databases are used for more simple relationship structures. In addition, graph databases typically require fewer joins than relational databases. As a result, graph databases can be faster and more efficient when it comes to handling complex data.
Are graph databases better than relational databases?
Yes to a large extent. Graph databases are better than relational databases because they are more flexible and can handle more complex data relationships. Relational databases are based on the table structure of data, which is difficult to change once the data is in the database. Graph databases, on the other hand, are based on the graph structure of data, which is easy to change. Considering that data is becoming increasingly complex, graph databases are far much better for most use cases where complex data manipulation is a priority.
What is a graph database not good for?
Graph databases are well suited for storing data with complex relationships, such as social networks or financial data. However, graph databases are not well suited for storing data that can be easily represented in a tabular format, such as product catalogs or customer orders.
You May Also Like:
Has this article aroused your interest in graph databases?
Explore more in-depth details of the concepts and practical applications of graph databases in this blog:
What is a graph database and what are its use cases - Definition, examples & trends